关于SPSS数据的录入和管理
归纳总结如何做数据的导入,样本数据简介和变量水平,文件水平数据等的管理
数据是统计研究的基础。用于分析的数据资料有两种:一种是原始资料,如调查问卷中的数据需要将它们录入进SPSS软件,建立数据文件;另一种是己经被录入为其他数据格式的资料,需要将其内容读入SPSS中。对于原始资料录入到SPSS的介绍,以调查问卷数据为例说明最为合适,因为通常调查问卷中的问题包括单选题、多选题和开放题等几种,基本上囊括了所有数据类型的SPSS录入情况。下面就以调查问卷数据的录入为例,说明SPSS的原始数据录入。
SPSS变量类型
SPSS中,变量类型总共有8种,这8种又可被归结为3种基本的类型,分别是日期型、字符型,数值型。数值型包括标准数值型、逗号数值型、圆点数值型、科学计数型、美元数值型、用户自定义型等6种类型。数值型变量是由0到9的阿拉伯数字和其他特殊符号,比如逗号、圆点等组成的,是SPSS中常用的变量类型。日期型变量是用来表示日期或者时间的,主要在时间序列分析中比较有用。字符型变量区分大小写字母,但不能进行数学运算。SPSS的数据录入涉及到“数据视图”和“变量视图”两个界面。在“变量视图”中输入变量的名称,然后根据数据的特性对“类型”、“宽度”、“小数”、“标签”、“值”、“缺失”等属性进行定义。如下图所示:

调查问卷
下面是一份9题的调查问卷:

在这份问卷中,包含了开放题、单选题和多选题,其中第1,3,5,9是开放题,题1,9是数值型开放题,3是字符型,5是日期型;第2,4,6题是单选题,第7,8题是多选题。
数据录入
前面提到调查问卷的问题大致有三类:开放题、单选题和多选题。
开放题录入
开放题的录入非常简单,首先在“变量视图”窗口定义好该问题涉及的变量,然后切换到“数据视图”输入变量的具体数值。需要注意:开放题的答案一般都是字符型变量,所以变量的“宽度”一定要合适设定以保证变量的具体取值能够被完整录入。以上面调查问卷的1,3,5,9题为例说明,如下图:

大家根据具体的题目答案,设置不同的变量类型与其性质。
单选题录入
对于单选题,可以采用“字符直接录入”、“字符代码 值标签”、“数值代码 值标签”三种方式录入数据,最常用的是第三种,用不同数据来代替问卷中的答案选项。上方调查问卷的第2,4,6题为例说明,如下图所示:
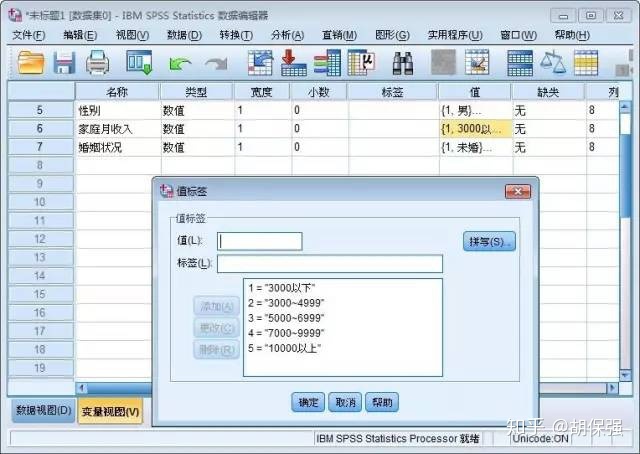
宽度和小数根据具体定义的值得大小来确定。
多选题录入
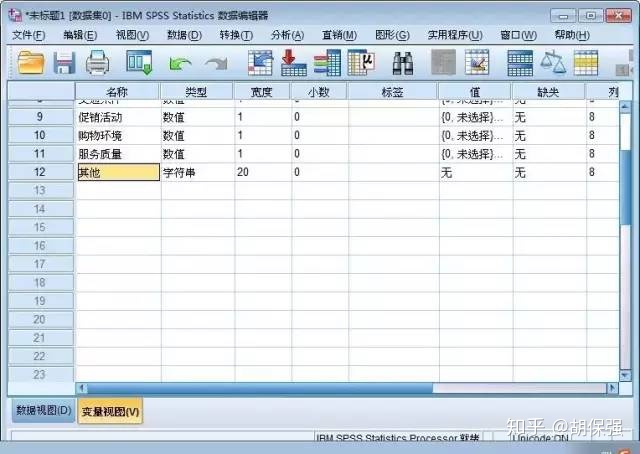
对于多选题的录入,常见的方法有两种:多重二分法和多重分类法。多重二分法是指对每一个选项都定义一个变量,这些变量都只有两个取值,分别代表选择和未选择。多重分类法就是讲多选题看做单选题的多次回答,所以变量的个数设置有赌博意味,可能出现变量过多或过少的情况。最保险的做法也就是有多少个选项设置多少个变量。所以多重二分法是更为常用的多选题录入办法。以问卷调查的第7、8题为例,如下图所示:

第8题属于半开放题,包含选择题和开放题。解决办法就是在设置第8题的开放选项变量时,将变量设置为字符型,宽度根据需要设置。
SPSS的样本数据介绍
样本文件都存放在SPSS的安装目录的【Samples】文件夹中,例如,22版的存放路径是:【SPSS】-【Statistics】-【22】-【Samples】;
不同的版本和安装情况,它们的存放路径会有不同,大家可以在安装文件夹中寻找。
SPSS对这些样本文件做了注释说明,下面是部分样本数据的注释说明:
accidents.sav; 该假设数据文件涉及某保险公司,该公司正在研究给定区域内汽车事故的年龄和性别风险因子。每个个案对应一个年龄类别和性别类别的交叉分类。
adl.sav;该假设数据文件涉及在确定针对脑卒中患者的建议治疗类型的优点方面的举措。医师将女性脑卒中患者随机分配到两组中的一组。第一组患者接受标准的物理治疗,而第二组患者则接受附加的情绪治疗。在进行治疗的三个月时间里,将为每个患者进行一般日常生活行为的能力评分并作为原始变量。
advert.sav;该假设数据文件涉及某零售商在检查广告支出与销售业绩之间的关系方面的举措。为此,他们收集了过去的销售数字以及相关的广告成本。
aflatoxin.sav;该假设数据文件涉及对谷物的黄曲霉毒素的检测,该毒素的浓度会因谷物产量的不同(不同谷物之间及同种谷物之间)而有较大变化。谷物加工机从8个谷物产量的每一个中收到16个样本并以十亿分之几 (PPB) 为单位来测量黄曲霉毒素的水平。
anorectic.sav;在研究厌食/暴食行为的标准症状参照时,研究人员对55名已知存在进食障碍的青少年进行了调查。其中每名患者每年都将进行四次检查,因此总观测数为220。在每次观测期间,将对这些患者按16种症状逐项评分。但71号和76号患者的症状得分均在时间点2缺失,47号患者的症状得分在时间点3缺失,因此有效观测数为217。
bankloan.sav;该假设数据文件涉及某银行在降低贷款拖欠率方面的举措。该文件包含850位过去和潜在客户的财务和人口统计信息。前700个个案是以前曾获得贷款的客户。剩下的150个个案是潜在客户,银行需要按高或低信用风险进行分类。
bankloan_binning.sav;该假设数据文件包含5,000位过去客户的财务和人口统计信息。
behavior.sav;在一个经典示例中,52名学生被要求以10点的标度对15种情况和15种行为的组合进行评价,该10点的标度从0=“极得体”到9=“极不得体”。平均值在个人值之上,值被视为相异性。
behavior_ini.sav;该数据文件包含behavior.sav的二维解的初始配置。
brakes.sav;该假设数据文件涉及某生产高性能汽车盘式制动器的工厂的质量控制。该数据文件包含对8台专用机床中每一台的16个盘式制动器的直径测量。盘式制动器的目标直径为322毫米。
breakfast.sav;在一项经典研究中,21名Wharton School MBA学生及其配偶被要求按照喜好程度顺序对15种早餐食品进行评价,从他们的喜好根据六种不同的情况加以记录,从“全部喜欢”到“只带饮料的快餐”。
breakfast-overall.sav;该数据文件只包含早餐食品喜好的第一种情况,即“全部喜欢”。
broadband_1.sav;该假设数据文件包含各地区订制了全国宽带服务的客户的数量。该数据文件包含4年期间85个地区每月的订户数量。
broadband_2.sav;该数据文件和broadband_1.sav一样,但包含另外三个月的数据。
car_insurance_claims.sav;在别处被提出和分析的关于汽车损坏赔偿的数据集。平均理赔金额可以当作其具有伽玛分布来建模,通过使用逆关联函数将因变量的平均值与投保者年龄、车辆类型和车龄的线性组合关联。提出理赔的数量可以作为刻度权重。
car_sales.sav;该数据文件包含假设销售估计值、订价以及各种品牌和型号的车辆的物理规格。订价和物理规格可以从http://edmunds.com和制造商处获得。
car_sales_uprepared.sav;这是car_sales.sav的修改版本,不包含字段的任何已转换版本。
carpet.sav;在常用示例中,有一家公司想要销售一种新型的地毯清洁用品。该公司希望调查以下会对消费者偏好产生影响的五个因素:包装设计、品牌名称、价格、优质家用品标志、以及退货保证。包装设计有三个因子级别,每个因子级别因刷体位置而不同;有三个品牌名称(K2R、Glory和 Bissell);有三个价格水平;最后两个因素各有两个级别(有或无)。十名消费者对这些因素所定义的22个特征进行了排序。变量优选包含对每个概要文件的平均等级的排序。低等级与高偏好相对应。此变量反映了对每个概要文件的偏好的总体度量。
carpet_prefs.sav;该数据文件所基于的示例和在carpet.sav中所描述的一样,但它还包含从10位消费者的每一位中收集到的实际排列顺序。消费者被要求按照从最喜欢到最不喜欢的顺序对22个产品概要文件进行排序。carpet_plan.sav中定义了变量PREF1到PREF22包含相关特征的标识。
catalog.sav;该数据文件包含某编目公司出售的三种产品的假设每月销售数据。同时还包括 5 个可能的预测变量的数据。
catalog_seasfac.sav;除添加了一组从“季节性分解”过程中计算出来的季节性因素和附带的日期变量外,该数据文件和catalog.sav是相同的。
cellular.sav;该假设数据文件涉及某便携式电话公司在减少客户流失方面的举措。客户流失倾向分被应用到帐户,分数范围从0到100。得到50分或更高分数的帐户可能会更换提供商。
ceramics.sav;该假设数据文件涉及某制造商在确定新型优质合金是否比标准合金具有更高的耐热性方面的举措。每个个案代表对一种合金的单独检验;个案中会记录合金的耐热极限。
cereal.sav;该假设数据文件涉及一份880人参于的关于早餐喜好的民意调查,该调查记录了参与者的年龄、性别、婚姻状况以及生活方式是否积极(根据他们是否每周至少做两次运动)。每个个案代表一个单独的响应者。
clothing_defects.sav;这是关于某服装厂的质量控制过程的假设数据文件。检验员要对工厂中每次大批量生产的服装进行抽样检测并清点不合格的服装的数量。
coffee.sav;这是关于六种冰咖啡的认知品牌形象的数据文件。对于23种冰咖啡特征属性中的每种属性,人们选择了由该属性所描述的所有品牌。为保密起见,六种品牌用AA、BB、CC、DD、EE 和FF来表示。
contacts.sav;该假设数据文件涉及一组公司计算机销售代表的联系方式列表。根据这些销售代表所在的公司部门及其公司的等级来对每个联系方式进行分类。同时还记录了最近一次的销售量、最近一次销售距今的时间和所联系公司的规模。
creditpromo.sav;该假设数据文件涉及某百货公司在评价最新信用卡促销的效果方面的举措。为此,随机选择了500位持卡人。其中一半收到了宣传关于在接下来的三个月内降低消费利率的广告。另一半收到了标准的季节性广告。
customer_dbase.sav;该假设数据文件涉及某公司在使用数据仓库中的信息来为最有可能回应的客户提供特惠商品方面的举措。随机选择客户群的子集并为其提供特惠商品,同时记录下他们的回应。
customer_information.sav;该假设数据文件包含客户邮寄信息,如姓名和地址。
customer_subset.sav;来自 customer_dbase.sav的拥有80个个案的子集。
debate.sav;该假设数据文件涉及在某政治辩论前后对该辩论的参与者所做的调查的成对回答。每个个案对应一个单独的响应者。
debate_aggregate.sav;该假设数据文件汇总了debate.sav中的回答。每个个案对应一个辩论前后的偏好的交叉分类。
demo.sav;这是关于购物客户数据库的假设数据文件,用于寄出每月的商品。将记录客户对商品是否有回应以及各种人口统计信息。
demo_cs_1.sav;该假设数据文件涉及某公司在汇编调查信息数据库方面的举措的第一步。每个个案对应不同的城市,并记录地区、省、区和城市标识。
demo_cs_2.sav;该假设数据文件涉及某公司在汇编调查信息数据库方面的举措的第二步。每个个案对应来自第一步中所选城市的不同的家庭单元格,并记录地区、省、区、市、子区和单元格标识。还包括设计前两个阶段的抽样信息。
demo_cs.sav;该假设数据文件包含用复杂抽样设计收集的调查信息。每个个案对应不同的家庭单元格,并记录各种人口统计和抽样信息。
dmdata.sav;该假设数据文件包含直销公司的人口统计学和购买信息。dmdata2.sav包含收到测试邮件的同一部分联系人的信息,而dmdata3.sav包含其余未收到测试邮件的联系人信息。
dietstudy.sav;该假设数据文件包含对 `Stillman diet`的研究结果。每个个案对应一个单独的主体,并记录其在实行饮食方案前后的体重(磅)以及甘油三酸酯的水平(毫克/100 毫升)。
dvdplayer.sav;这是关于开发新的DVD播放器的假设数据文件。营销团队用原型收集了焦点小组数据。每个个案对应一个单独的被调查用户,并记录他们的人口统计信息及其对原型问题的回答。
german_credit.sav;该数据文件取自加州大学欧文分校的Repository of Machine Learning Databases中的 `German credit` 数据集。
grocery_1month.sav;该假设数据文件是在数据文件grocery_coupons.sav的基础上加上了每周购物“累计”,所以每个个案对应一个单独的客户。所以,一些每周更改的变量消失了,而且现在记录的消费金额是为期四周的研究过程中的消费金额之和。
grocery_coupons.sav;该假设数据文件包含由重视顾客购物习惯的杂货连锁店收集的调查数据。对每位顾客调查四周,每个个案对应一个单独的顾客周,并记录有关顾客购物地点和方式的信息(包括那一周里顾客在杂货上的消费金额)。
guttman.sav;Bell创建了一个表,用来阐释可能的社会群体。Guttman引用了该表的一部分,其中包括五个变量,用于描述以下七个理论社会群体的社会交往、对群体的归属感、成员的物理亲近度以及关系正式性:观众(比如在足球比赛现场的人们)、听众(比如在剧院或听课堂讲座的人们)、公众(比如报纸或电视观众)、组织群体(与观众类似但具有紧密的关系)、初级群体(关系密切)、次级群体(自发组织)及现代社区(因在物理上亲近而导致关系松散并需要专业化服务)。
health_funding.sav;该假设数据文件包含关于保健基金(每 100 人的金额)、发病率(每 10,000 人的比率)以及保健提供商拜访率(每 10,000 的比率)的数据。每个个案代表不同的城市。
hivassay.sav;该假设数据文件涉及某药物实验室在开发用于检测 HIV 感染的快速化验方面的举措。化验结果为八个加深的红色阴影,如果有更深的阴影则表示感染的可能性很大。用2,000份血液样本来进行实验室试验,其中一半受到 HIV 感染而另一半没有受到感染。
hourlywagedata.sav;该假设数据文件涉及在政府机关和医院工作的具有不同经验水平的护士的时薪。
insurance_claims.sav;该假设数据文件涉及某保险公司,该公司希望构建一个模型用于标记可疑的、具有潜在欺骗性的理赔。每个个案代表一次单独的理赔。
insure.sav;该假设数据文件涉及某保险公司,该公司正在研究指示客户是否会根据 10 年的人寿保险合同提出理赔的风险因子。数据文件中的每个个案代表一副根据年龄和性别进行匹配的合同,其中一份记录了一次理赔而另一份则没有。
如何导入外部数据:
数据类型
数据的打开方式有下面三种:分别打开SPSS默认数据类型,数据库类型(Excel和Access)和文本数据类型。

将所有数据类型列表如下:

打开数据
SPSS的程序文件夹自带样本数据,这些数据可以用于各个统计分析模块的运算。这些数据存放在SPSS程序文件夹下的`Samples`文件夹中。
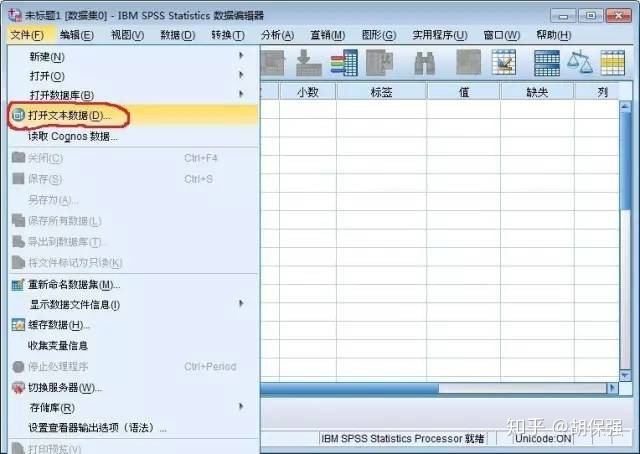
以文本数据类型的录入为例说明SPSS导入外部数据的操作过程。找到“Samples”文件夹中的demo.txt的文件,直接双击打开,如下图:

很多监测或检测设备记录的数据都是用txt文本格式输出的,例如工厂中的金重检机的产品重量数据,油炸机的油温监测数据、流体管道的流量数据等等。
下面用SPSS打开demo.txt文件,过程如下:


中间省略了导入数据的条件选择过程,这个过程与Excel导入外部数据的过程基本相同。大家在具体操作的过程中需要事先对数据的存储方式有了解,才能在导入的过程中做出正确的选择,得到满意的数据导入结果。
其他数据类型的导入过程大同小异,这里就不过多叙述。在SPSS的样本数据文件夹“Samples”中,包含demo.xls、demo.mdb等其他类型的文件,可以自己练习导入的操作。

- 上一篇:ps选择功能的快捷键
- 下一篇:ps怎么下载雪花笔刷并使用?
评论列表